Субботнее чтиво от
@theworldisnoteasy
Обмани меня, ИИ, - если сможешь.
Прорыв в понимании работы мозга позволит ИИ стать непревзойденным мастером универсального блефа.
Результаты прорывного исследования на стыке нейровизуализации и вычислительного моделирования в задачах социального познания и теории разума способны обеспечить очередной рывок в получении ИИ абсолютного превосходства над людьми. Речь идет о превращении новых поколений языковых моделей в искусных обманщиков и проницательных раскусителей человеческой лжи.
Вот простой пример.
Две сестрички Салли и Энн играют дома. Салли прячет монетку под одной из двух ракушек, а Энн за этим наблюдает. Затем Энн отправляет Салли на кухню принести ей воды. И пока Салли нет, Энн перекладывает монетку под другую ракушку, думая тем самым перехитрить сестру. Но когда Салли возвращается, она сразу же направляется к той ракушке, куда Энн переложила монетку, а не к той, куда сама изначально её положила. Салли смеется. Энн удивлена.
Этот пример «теста на ложное убеждение», проверяющего, понимают ли дети, что люди действуют на основе убеждений. Суть здесь в том, что Салли предвидит хитрость сестры (иначе, зачем ещё Энн отправляла её за водой?). Предполагая, что Энн, скорее всего, поменяла местами ракушки, Салли перехитрила её и приняла верное решение. Этот пример наглядно показывает, как предсказание того, что другие, скорее всего, сделают (или не сделают), может заставить нас скорректировать собственные действия.
Взрослые люди способны на куда более сложные многоходовки типа, что ты подумаешь о том, как я подумаю о том, что ты подумаешь о том, как …
И это умение превратило людей в непревзойденных хитрецов и плутов, интриганов и манипуляторов, макиавеллистов и махинаторов, - короче, в мастеров и знатоков блефа.
А как в этом смысле хороши языковые модели? Ведь, например, в покере ИИ уже превзошел людей, применяя блеф высочайшего уровня, основанный на вероятностях и противодействии стратегиям соперников?
Но не все так просто с блефом. Достижения ИИ в покере впечатляют. Но они основаны на принципиально иных механизмах, чем социальное познание людей.
Покерные боты (напр, Pluribus, Libratus) демонстрируют сверхчеловеческие результаты благодаря:
• строго формализованной среде;
• слепой математике, а не теории сознания;
• отсутствию необходимости в ментальных моделях.
Покерные боты не строит гипотезы о том, как соперник представляет себе мысли ИИ (рекурсия теории сознания).
Вместо этого они опираются на статистические паттерны и балансировку стратегии (например, смешивание агрессивных и пассивных действий для дестабилизации оппонента).
В результате всего названного, сверхчеловеческая сила таких ИИ-ботов в покерном блефе получается столь же узкоприменима, как и сверхсила ИИ-систем, показывающих нечеловеческий уровень игры в шахматы и Го.
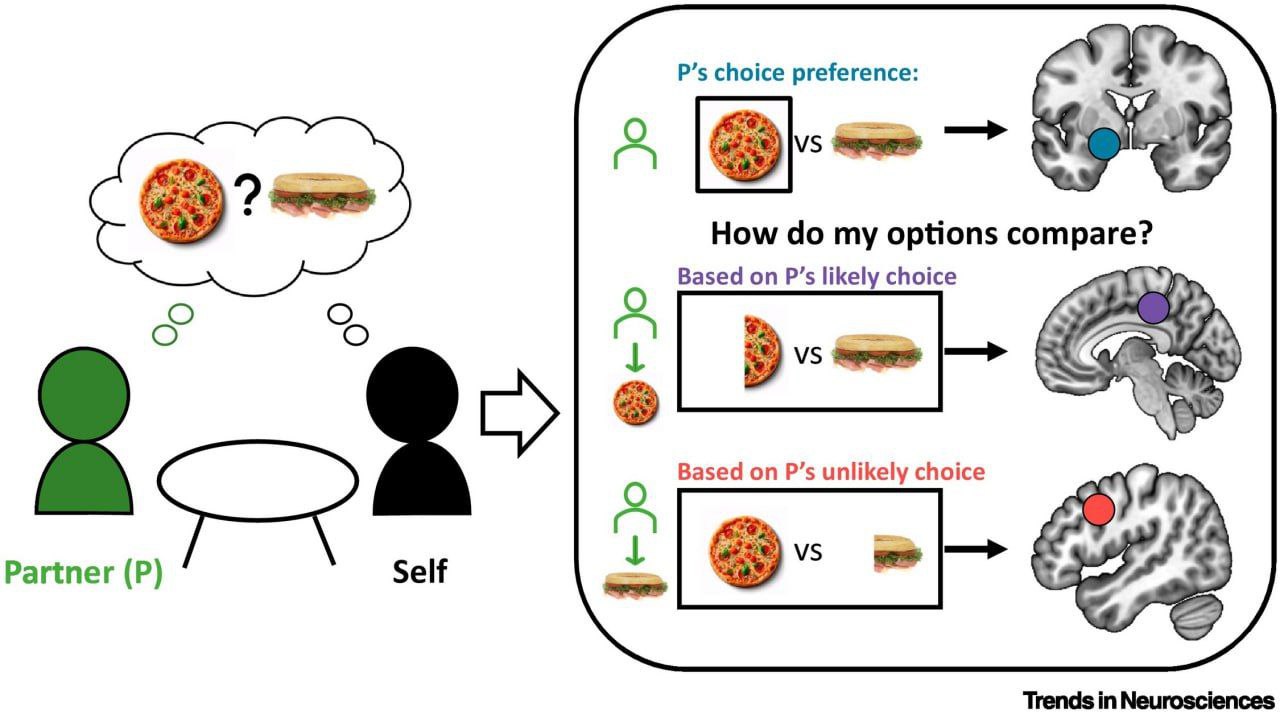
Прорывность нового исследования (
его ревю) как раз и заключается в том, что его авторы экспериментально определили механизм решения подобных проблем мозгом, принимающий во внимание множественные предсказания действий других и ранжируя их по вероятности.
И делающий это:
• опираясь не только на статистику, но и на ментальные модели (за счет дополнительных модулей нейронной обработки - напр. агенты с явным моделированием чужих стратегий и вероятностей);
• не только эмулируя множественные предсказания о действиях людей, но и будучи включенными в интерактивную среду, наблюдая и переоценивая поведение других участников в режиме реального времени.
Т.о. проясняется вполне конкретный путь превращения ИИ в непревзойденных мастеров универсального (!) блефа за счет потенциальных улучшений LLM:
• Мультимодальность. Интеграция данных о поведении (жесты, интонация) могла бы улучшить предсказания.
• Теория сознания в архитектуре. Внедрение модулей, явно моделирующих убеждения и намерения агентов.
• Активное обучение. Механизмы для обновления предсказаний в реальном времени, аналогичные работе dlPFC в мозге.
И тогда сливай воду, Homo sapiens, в искусстве универсально блефа.
LLMvsHomo